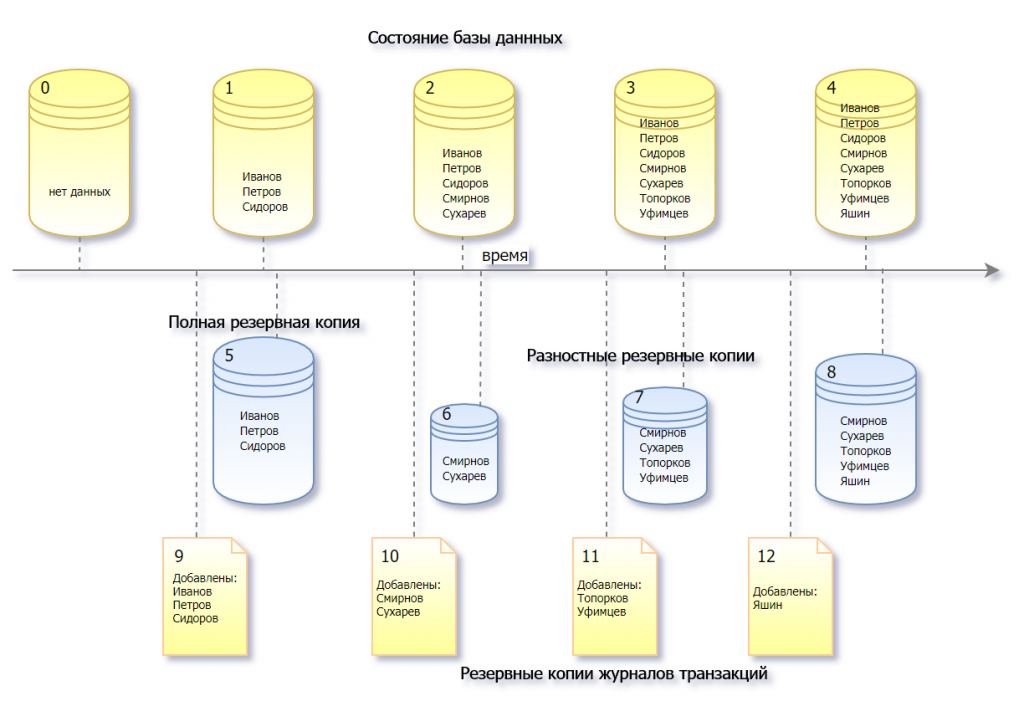
Архив журналов
Можно создавать архив wal файлов. Такой архив может быть файловым или потоковым.
Файловый архив:
- сегменты WAL копируются в архив по мере заполнения;
- механизм работает под управлением сервера;
- неизбежны задержки попадания данных в архив.
Потоковый архив:
- в архив постоянно записывается поток журнальных записей;
- требуются внешние средства;
- задержки минимальны.
Чтобы запустить файловый архив нужно запустить процесс archiver. Для этого нужно настроить 3 параметра:
- archive_mode = on;
- archive_command – команда shell для копирования сегмента WAL в отдельное хранилище (или скрипт);
- archive_timeout – максимальное время для переключения на новый сегмент WAL (если по окончанию этого времени сегмент wal не заполнится, то переключение всё равно произойдет на новый файл). Даже если wal файл до конца не заполнился он все равно будет весить 16 МБ, поэтому слишком маленьким таймаут лучше не делать.
При заполнении сегмента WAL вызывается команда archive_command если команда завершается со статусом 0, сегмент удаляется если команда возвращает не 0 (в частности, если команда не задана), сегмент остается до тех пор, пока попытка не будет успешной.
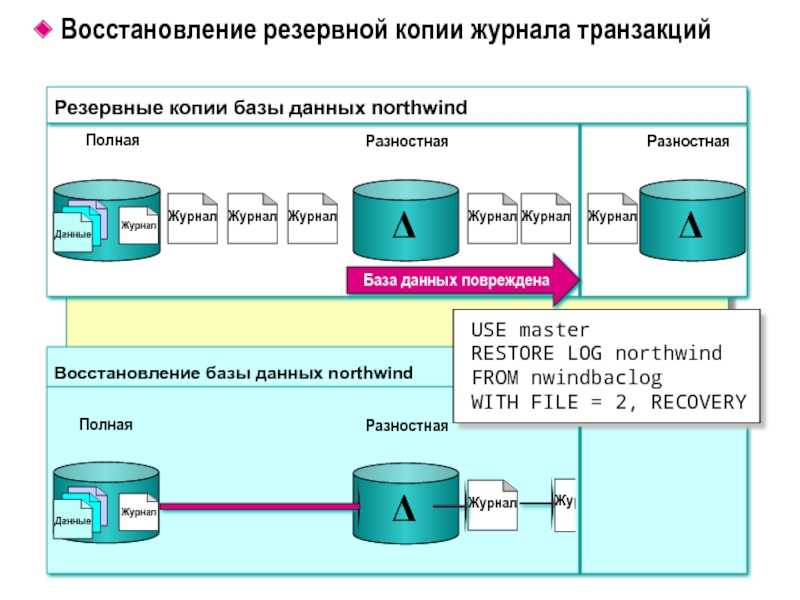
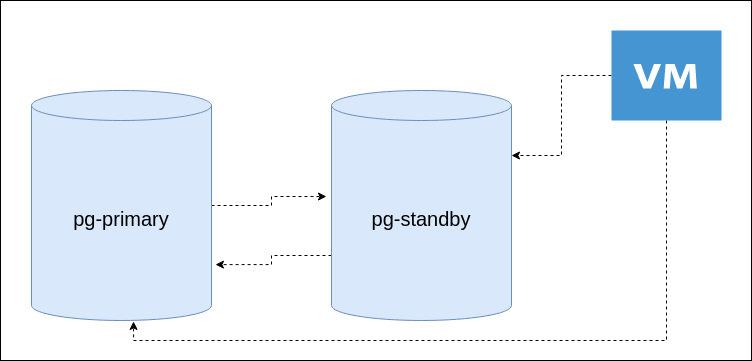
При настроенном архивировании, на резервном сервере мы можем восстановиться на любой момент времени.
Для потокового архива используется утилита pg_receivewal. Она подключается по протоколу репликации и может использовать слот репликации. Затем она направляет поток записей WAL в файлы-сегменты. Стартовая позиция – начало текущего сегмента. В отличии от файлового архивирования записи wal передаются постоянно.
При восстановлении базы данных, когда есть данные на определённый момент времени и архив wal файлов. Нужно создать файл $PGDATA/recovery.conf в котором указать, откуда брать wal файлы, и включить сервер.
Мотивация
Репликация – это очень просто. Репликация означает копирование состояние одного сервера на другой. То есть – любые изменения, примененные на основной сервер (master) будут скопированы на его “заместителя” (slave). Для чего это нужно:
- Для распределения нагрузки. Slave не может записывать данные, но с него можно эти данные читать. По личному опыту, более 80% нагрузки на базу данных – это именно чтение в том или ином виде. Slave (или несколько) позволяют разгрузить мастер. Установка нескольких дешевых серверов чаще всего обходится дешевле, чем обновления одного, но дорогого (горизонтальное масштабирование дешевле вертикального. В некоторых случаях мешает закон Амдаля, но у нас не тот случай).
- Для построения отказоустойчивых систем. В случае, если с мастером что-то случилось – превратить slave в master можно буквально за секунды, это снижает время простоя. Восстановление из резервной копии займет много больше времени. Кроме того, состояние slave-а будет максимально приближено к состоянию master-а на момент отказа. Бэкапы обычно делаются по расписанию. То есть – все данные, записанные после создания резервной копии и до отказа мастера можно считать потерянными безвозвратно.
Как и у всякой технологии, у репликации есть ограничения:
- Репликация в PostgreSQL – исключительно однонаправленная (master -> slave). PostgreSQL не поддерживает мультимастер (есть внешние решения, но они выходят за рамки этой статьи)
- Репликация дополняет бэкап, но не заменяет его. Реплика спасет данные, если с мастер-сервером что-то случилось: отказ электричества, сервер сгорел, жесткие диски умерли, пожар в ЦОД, правоохранительные органы изъяли оборудование и т.д. Репликация никак не поможет при логической ошибке (код запорол данные) или ошибке оператора (“призрак человека с консолью”).
- Особенность именно PostgreSQL — репликация возможна только всего сервера целиком, нельзя выбрать базы, которые будут реплицироваться (или не будут).
- По умолчанию репликация — асинхронная. Это значит, что мастер пишет данные постоянно, а slave вытаскивает изменения и применяет их у себя по мере возможности. Вообще, в норме это не вызывает проблем. Но, если вдруг у slave возникли с этим проблемы (мастер несравнимо мощнее и slave не успевает применять изменения, или проблемы с сетью между мастером и slave) – master “убежит” вперед. Данные при этом потеряны не будут, и slave догонит мастер, как только сможет. Такую ситуацию несложно отслеживать (дальше покажу, как), просто нужно иметь это ввиду. Репликацию можно сделать синхронной, чтобы гарантировать абсолютную консистентность данных между серверами, но это удорожает транзакции – производительность записи упадет, а нагрузка – вырастет.
- Репликация использует отдачу WAL-сегментов с мастера на slave-ы. Эти сегменты надо на мастере где-то хранить, то есть нужно запланировать дополнительное место для них.
- Репликация возможна только между серверами с общей мажорной версией (то есть реплицироваться 9.5 -> 9.5 можно, а с 9.4 -> 10.0 – нельзя). На всякий случай напомню, что до версии 10.0 обновления 9.4 -> 9.5 считались мажорными, а не минорными. У разных версий разный формат хранения данных.
- потоковая репликация возможна только в PostgreSQL 9 и выше. Она не работает в 7 и 8 версиях.
Ручное резервное копирование базы данных
В этом случае используется утилита «Управление схемами БД», которая входит в состав АПК «Бастион-2».
СУБД Oracle
Для входа в программу выбираем клиент «XE», псевдоним бд «XE», пароль SYSTEM «устанавливается во время создания бд»
![]()
В окне программы нажимаем кнопку «Экспортировать в файл». Далее вводим имя файла и пароль к схеме pro_bastion, выбираем утилиту, с помощью которой будем делать экспорт (рекомендуется Data Pump)
![]()
Ждем окончания экспорта
![]()
Экспорт завершен
![]()
СУБД PostgreSQL
Для входа в программу вводим пароль пользователя postgres, указанный во время установки СУБД
В окне программы нажимаем кнопку «Экспортировать в файл» и указываем путь, по которому будет сохранена копия
![]()
Ждем окончания экспорта
![]()
Экспорт завершен
Подготовка нового сервера к поднятию копии postgesql
Стандартные действия после установки системы
На новом сервере произвёл:
- обновление системы
- перезагрузка
- подключение репо postgresql
Памятуя о версии на исходном сервере, производим установку конкретной версии posgresql:
Устанавливаем пакет для возможности блокировки пакетов от апгрейда и выполняем блокировку пакетов :
При необходимости, актуальный список залоченных пакетов смотрим здесь .
Монтирование большого раздела к /var/lib/pgsql
На новом сервер наблюдаем отдельный большой раздел 1.5TB подмонтрованный к . Создадим на нём каталог pgsql и прочее:
Добавим в /etc/fstab следующую строку для автоматического биндинга к :
Важно!!! Если после последней строки в файле не будет добавлена пустая строка, то сервер зависнет на этапе загрузки системы. Не помню причины этого явления, поэтому примите на веру, если не знали
6. Настройка клиентских пк для поиска ключей в 1с
Создаем директорию
mkdir /opt/1C/v8.3/X86_64/conf
| 1 | mkdiropt1Cv8.3X86_64conf |
И создаем файл с настройками для поиска аппаратной защиты
nano /opt/1C/v8.3/X86_64/conf/nethasp.ini
| 1 | nanoopt1Cv8.3X86_64confnethasp.ini |
NH_IPX = Disabled
NH_NETBIOS = Disabled
NH_TCPIP = Enabled
NH_SERVER_ADDR = 10.85.66.5
NH_PORT_NUMBER = 475
NH_TCPIP_METHOD = UDP
NH_USE_BROADCAST = Disabled
|
1 |
NH_COMMON NH_IPX=Disabled NH_NETBIOS=Disabled NH_TCPIP=Enabled NH_IPX NH_NETBIOS NH_TCPIP NH_SERVER_ADDR=10.85.66.5 NH_PORT_NUMBER=475 NH_TCPIP_METHOD=UDP NH_USE_BROADCAST=Disabled |
Где:
10.85.66.5 — адрес сервера с установленным ключом
475 — порт
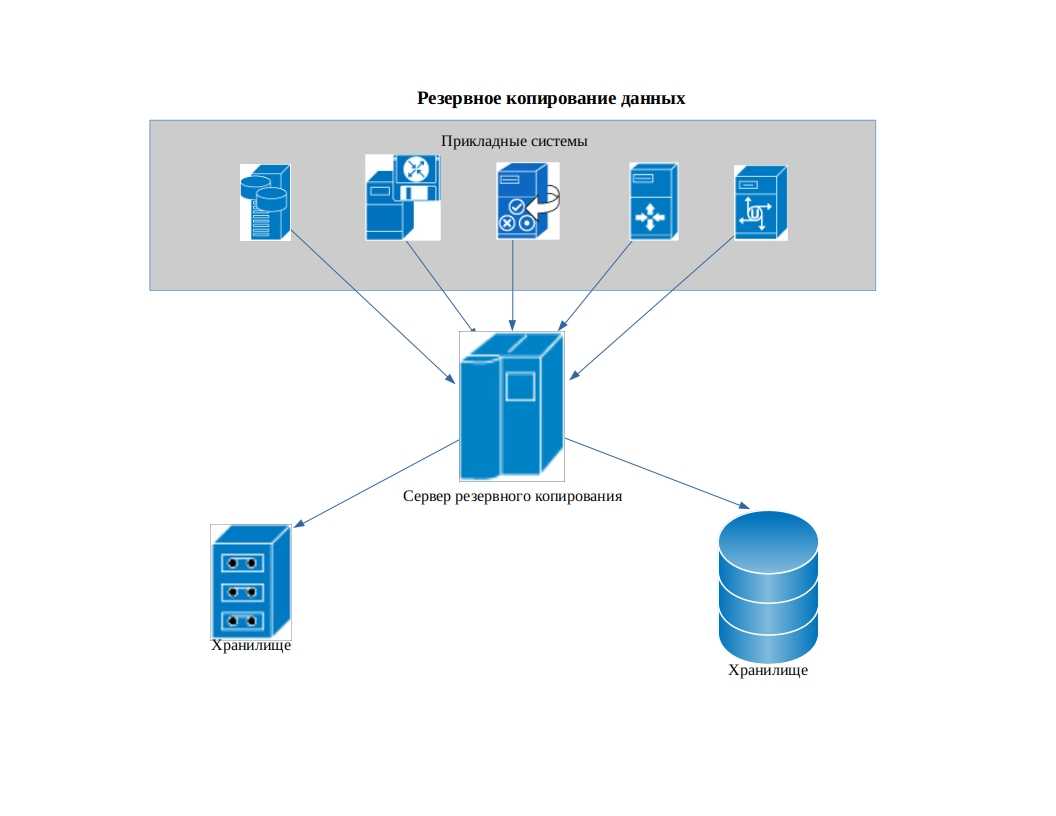
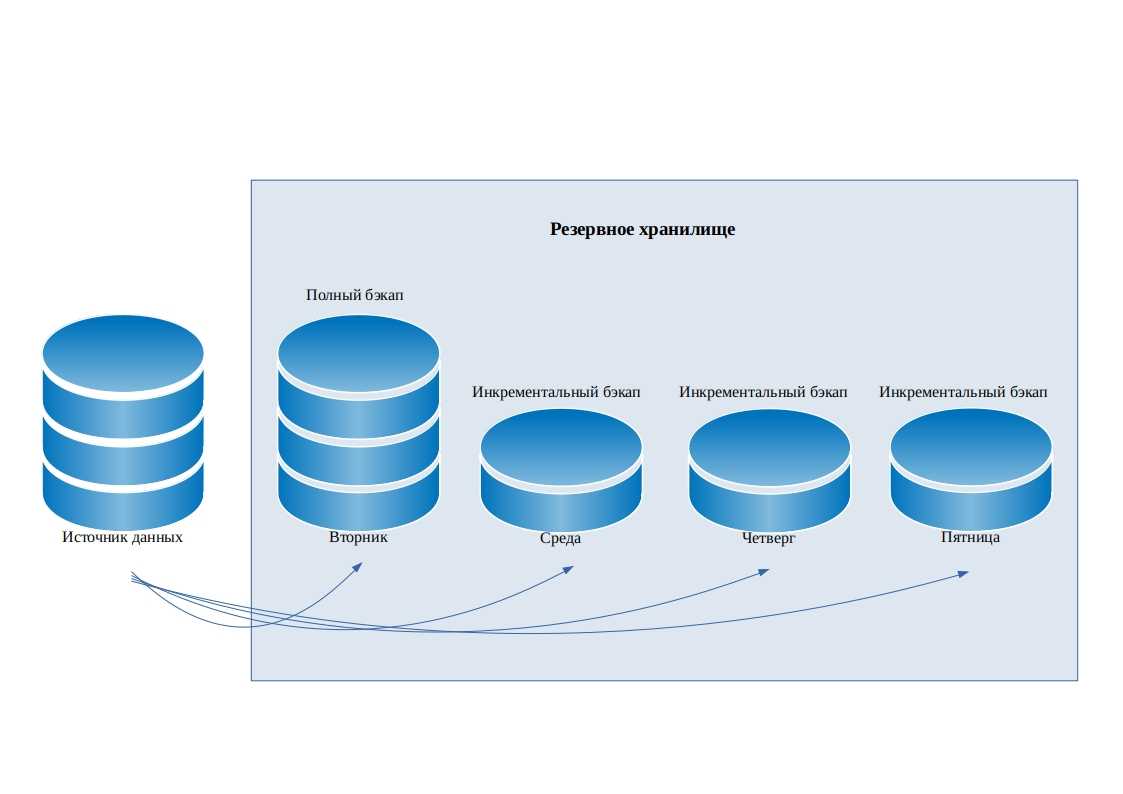
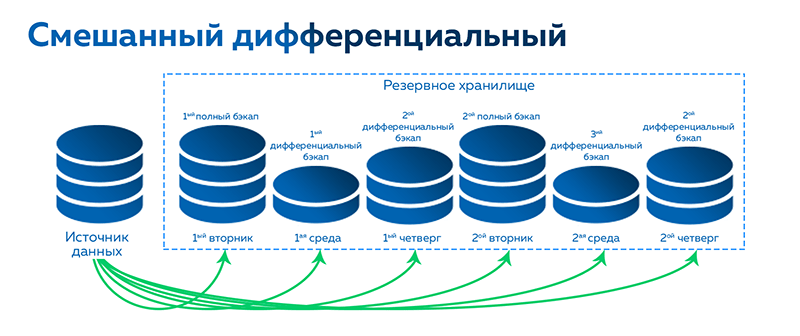
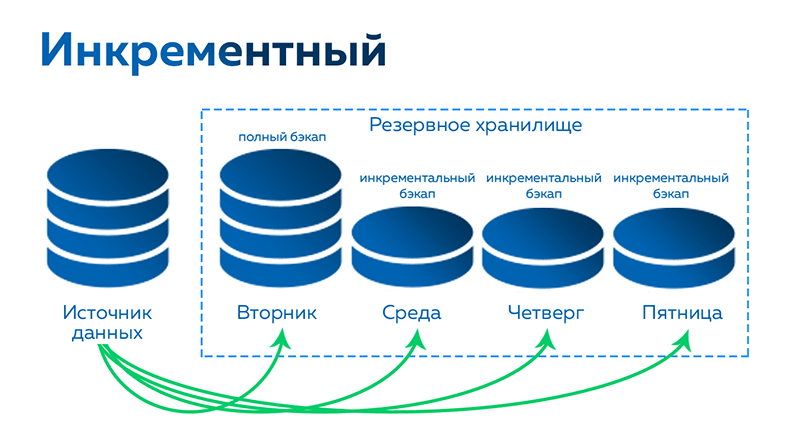
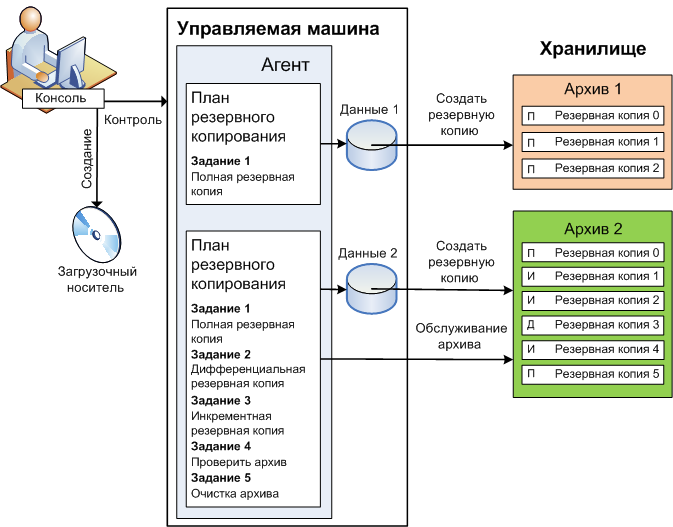
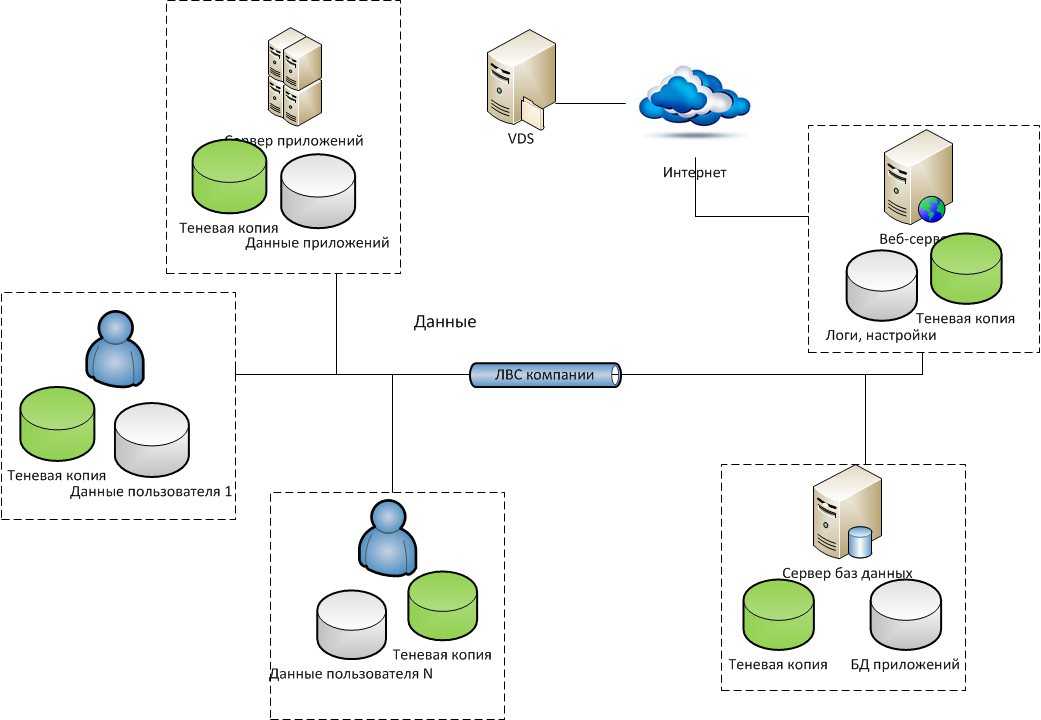
Создание резервных копий
Пользователь и пароль
Если резервная копия выполняется не от учетной записи postgres, необходимо добавить опцию -U с указанием пользователя:
pg_dump -U dmosk -W users > /tmp/users.dump
* где dmosk — имя учетной записи; опция W потребует ввода пароля.
Сжатие данных
Для экономии дискового пространства или более быстрой передачи по сети можно сжать наш архив:
pg_dump users | gzip > users.dump.gz




![Резервное копирование и восстановление postgresql [айти бубен]](https://clipof.ru/wp-content/uploads/1/4/9/14951ce2d25f14d1af33ccc9462c9871.jpeg)
Скрипт для автоматического резервного копирования
PGPASSWORD=password export PGPASSWORD pathB=/backup dbUser=dbuser database=db
find $pathB \( -name “*-1.*” -o -name “*-?.*” \) -ctime +61 -delete pg_dump -U $dbUser $database | gzip > $pathB/pgsql_$(date “+%Y-%m-%d”).sql.gz
* где password — пароль для подключения к postgresql; /backup — каталог, в котором будут храниться резервные копии; dbuser — имя учетной записи для подключения к БУБД. * данный скрипт сначала удалит все резервные копии, старше 61 дня, но оставит от 15-о числа как длительный архив. После при помощи утилиты pg_dump будет выполнено подключение и резервирование базы db. Пароль экспортируется в системную переменную на момент выполнения задачи.
Для запуска резервного копирования по расписанию, сохраняем скрипт в файл, например, /scripts/postgresql_dump.sh и создаем задание в планировщике:
3 0 * * * /scripts/postgresql_dump.sh
* наш скрипт будет запускаться каждый день в 03:00.
На удаленном сервере
Если сервер баз данных находится на другом сервере, просто добавляем опцию -h:
pg_dump -h 192.168.0.15 users > /tmp/users.dump
* необходимо убедиться, что сама СУБД разрешает удаленное подключение. Подробнее читайте инструкцию Как настроить удаленное подключение к PostgreSQL.
Дамп определенной таблицы
Запускается с опцией -t или –table= :
pg_dump -t students users > /tmp/students.dump
* где students — таблица; users — база данных.
Размещение каждой таблицы в отдельный файл
Также называется резервированием в каталог. Данный способ удобен при больших размерах базы или необходимости восстанавливать отдельные таблицы. Выполняется с ипользованием ключа -d:
pg_dump -d customers > /tmp/folder
* где /tmp/folder — путь до каталога, в котором разместяться файлы дампа для каждой таблицы.
Только схемы
Для резервного копирования без данных (только таблицы и их структуры):
pg_dump –schema-only users > /tmp/users.schema.dump
Использование pgAdmin
Данный метод хорошо подойдет для компьютеров с Windows и для быстрого создания резервных копий из графического интерфейса.
Запускаем pgAdmin – подключаемся к серверу – кликаем правой кнопкой мыши по базе, для которой хотим сделать дамп – выбираем Резервная копия:
![]()
В открывшемся окне выбираем путь для сохранения данных и настраиваемый формат:
![]()
При желании, можно изучить дополнительные параметры для резервного копирования:
![]()
После нажимаем Резервная копия – ждем окончания процесса и кликаем по Завершено.
24.1.3. Handling Large Databases
Some operating systems have maximum file size limits that cause problems when creating large pg_dump output files. Fortunately, pg_dump can write to the standard output, so you can use standard Unix tools to work around this potential problem. There are several possible methods:
Use compressed dumps. You can use your favorite compression program, for example gzip:
pg_dump dbname | gzip > filename.gz
Reload with:
gunzip -c filename.gz | psql dbname
or:
cat filename.gz | gunzip | psql dbname
Use split. The split command allows you to split the output into smaller files that are acceptable in size to the underlying file system. For example, to make chunks of 1 megabyte:
pg_dump dbname | split -b 1m - filename
Reload with:
cat filename* | psql dbname
Use pg_dump’s custom dump format. If PostgreSQL was built on a system with the zlib compression library installed, the custom dump format will compress data as it writes it to the output file. This will produce dump file sizes similar to using gzip, but it has the added advantage that tables can be restored selectively. The following command dumps a database using the custom dump format:
pg_dump -Fc dbname > filename
A custom-format dump is not a script for psql, but instead must be restored with pg_restore, for example:
pg_restore -d dbname filename
See the pg_dump and pg_restore reference pages for details.
For very large databases, you might need to combine split with one of the other two approaches.
Решение
Для определения расположения файлов на дисках в PostgreSQL есть понятие Табличное пространство(TABLSEPACE). Разные табличные пространства можно размещать как на разных, так и на одном диске, хотя в последнем смысла не так много.
По умолчанию создается табличное пространство pg_default, у меня для версии 9.6 размещен в каталоге /var/lib/postgresql/9.6/main/base/.
Создание табличного пространства
Для создания табличного пространства необходимо заранее создать каталог в котором оно будет храниться, пользоватеть от которого запущена служба сервера PostgreSQL должен быть владельцем, катлог должен быть пустым.
По условию задачи табличное пространство необходимо разместить в каталоге /mnt/POINT_01/pg_base/, создаем его и пользователя postgres сделаем владельцем
# mkdir /mnt/POINT_01/pg_base # chown -R postgres:postgres /mnt/POINT_01/pg_base
Для дальнейших действий необходимо подключиться к сервру через pgAdmin или воспользоаться оболочкой psql. В pgAdmin можно выполнять команды графически так и запросами, в psql только запросами. Буду описывать графический вариант, а затем запрос, кторая выполнит теже действия.
Теперь создадим новое табличное пространство, назовем его point_01, в pgAdmin разворачиваем ветку Табличные пространства.
![]()
В ветке по нажатию ПКМ откроется меню, выбираем пункт Новый tablespace, в появившейся форме указываем название и местонахождение, и нажимаем кнопку OK. В ветке появится созданное тобличное пространство.
![]()
Запрос:
CREATE TABLESPACE point_01 LOCATION '/mnt/DEPOT_01/pg_base'
Перенос БД в другое табличное пространтсво
В ветке БД кликаем ПКМ по нужной ИБ, переходим в свойства на закладу Определение и выбираем необходимое табличное простарнство, и нажимаем кнопку OK.
![]()
После некоторого ожидания диалог закроется, база перенесена в другое табличное пространство.
Запрос:
ALTER DATABASE alt_production SET TABLESPACE point_01
Если c БД были установлены соединения, то выведется сообщение об шибке, например:
ОШИБКА: база данных "alt_production " занята другими пользователями DETAIL: Эта база данных используется ещё в 1 сеансе. ********** Ошибка ********** ОШИБКА: база данных "alt_production " занята другими пользователями SQL-состояние: 55006 Подробности: Эта база данных используется ещё в 1 сеансе.
Для завершения всех соединений с БД необходимо выполнить запрос описанный ниже и повторить перенос:
SELECT pg_terminate_backend (pg_stat_activity.pid) FROM pg_stat_activity WHERE pg_stat_activity.datname = 'alt_production ';
Завершающие действия
Копирование дампа на новый сервер
В нашем случае прямое ssh-соединение между серверами отсутствует, поэтому скопируем полученный дамп через форпост, который доступен из обоих сегментов сети.
Сейчас мы находимся на промежуточном сервере. Сначала подключаемся по ssh к одному из серверов, на каковом сервере открывается локальный порт 50000, который связывается с портом 22 другого сервера (через промежуточный сервер!):
Теперь, находясь на сервере 10.0.0.1 (что видно по приглашению командной строки) помним, что постучавшись на локальный порт , мы, на самом деле, стучимся на , но не на прямую, а через промежуточный сервер.

Поэтому здесь же запускаем процесс копирования с докачкой и проверкой. Копируем дамп и файлы настроек:
В результате этой команды, наш дамп, через промежуточный сервер, будет залит на новый сервер.
Перезагрузка для проверки
Использованный материал:
How to restrict yum to install or upgrade a package to a fixed specific package version?
25.1. SQL Dump Chapter 25. Backup and Restore
2. Установка 1С сервера
Скачиваем с сайта https://releases.1c.ru/ архив с deb пакетами 1С сервера и передаем на наш сервер. Можно воспользоваться WinSCP если используете Windows, для Linux можно воспользоваться scp
scp deb64_8_3_17_2256.tar.gz user@10.21.2.167:/home/user
| 1 | scp deb64_8_3_17_2256.tar.gz user@10.21.2.167homeuser |
Где:
deb64_8_3_17_2256.tar.gz — 1С архив
user@10.21.2.167 — Пользователь и адрес сервера куда передаем
:/home/user — Директория назначения
Архив лучше распаковать в отдельную директория
mkdir 1c-server
mv deb64_8_3_17_2256.tar.gz 1c-server/
cd 1c-server/
tar xzvf deb64_8_3_17_2256.tar.gz
|
1 |
mkdir1c-server mv deb64_8_3_17_2256.tar.gz1c-server cd1c-server tar xzvf deb64_8_3_17_2256.tar.gz |
Проверяем файлы которые распаковали
ls
| 1 | ls |
1c-enterprise83-common_8.3.17-2256_amd64.deb 1c-enterprise83-server_8.3.17-2256_amd64.deb 1c-enterprise83-ws-nls_8.3.17-2256_amd64.deb
1c-enterprise83-common-nls_8.3.17-2256_amd64.deb 1c-enterprise83-server-nls_8.3.17-2256_amd64.deb deb64_8_3_17_2256.tar.gz
1c-enterprise83-crs_8.3.17-2256_amd64.deb 1c-enterprise83-ws_8.3.17-2256_amd64.deb license-tools
|
1 |
1c-enterprise83-common_8.3.17-2256_amd64.deb1c-enterprise83-server_8.3.17-2256_amd64.deb1c-enterprise83-ws-nls_8.3.17-2256_amd64.deb 1c-enterprise83-common-nls_8.3.17-2256_amd64.deb1c-enterprise83-server-nls_8.3.17-2256_amd64.debdeb64_8_3_17_2256.tar.gz 1c-enterprise83-crs_8.3.17-2256_amd64.deb1c-enterprise83-ws_8.3.17-2256_amd64.deblicense-tools |
Для установки 1С сервера с поддержкой русского языка вам нужны пакеты в названии которых не встречается nsl
Ставим 1С сервер и запускаем его
dpkg -i 1c-enterprise83-common_8.3.17-2256_amd64.deb 1c-enterprise83-server_8.3.17-2256_amd64.deb 1c-enterprise83-ws_8.3.17-2256_amd64.deb
| 1 | dpkg-i1c-enterprise83-common_8.3.17-2256_amd64.deb1c-enterprise83-server_8.3.17-2256_amd64.deb1c-enterprise83-ws_8.3.17-2256_amd64.deb |
systemctl enable srv1cv83.service
| 1 | systemctl enable srv1cv83.service |
systemctl start srv1cv83.service
| 1 | systemctl start srv1cv83.service |
systemctl status srv1cv83.service
| 1 | systemctl status srv1cv83.service |
И проверяем состояние службы 1С
● srv1cv83.service — LSB: Starts and stops the 1C:Enterprise daemons
Loaded: loaded (/etc/init.d/srv1cv83; generated)
Active: active (exited) since Tue 2021-09-14 15:43:29 +05; 58s ago
Docs: man:systemd-sysv-generator(8)
Process: 6495 ExecStart=/etc/init.d/srv1cv83 start (code=exited, status=0/SUCCESS)
CPU: 80ms
сен 14 15:43:23 test systemd: Starting LSB: Starts and stops the 1C:Enterprise daemons…
сен 14 15:43:23 test su: (to usr1cv8) root on none
сен 14 15:43:23 test su: pam_unix(su-l:session): session opened for user usr1cv8(uid=998) by (uid=0)
сен 14 15:43:23 test su: pam_unix(su-l:session): session closed for user usr1cv8
сен 14 15:43:29 test srv1cv83: Starting 1C:Enterprise 8.3 server: OK
сен 14 15:43:29 test systemd: Started LSB: Starts and stops the 1C:Enterprise daemons.
|
1 |
●srv1cv83.service-LSBStarts andstops the1CEnterprise daemons Loadedloaded(etcinit.dsrv1cv83;generated) Activeactive(exited)since Tue2021-09-14154329+05;58sago Docsmansystemd-sysv-generator(8) Process6495ExecStart=etcinit.dsrv1cv83 start(code=exited,status=SUCCESS) CPU80ms сен14154323test su6507(tousr1cv8)root on none сен14154323test su6507pam_unix(su-lsession)session opened foruser usr1cv8(uid=998)by(uid=) сен14154323test su6507pam_unix(su-lsession)session closed foruser usr1cv8 сен14154329test srv1cv836495Starting1CEnterprise8.3serverOK сен14154329test systemd1Started LSBStarts andstops the1CEnterprise daemons. |
Если получили ошибку что такой службы нет то нужно создать символическую ссылку на запуск вручную
Для платформы до 8.3.20 и ниже
ln -s /opt/1cv8/x86_64/8.3.17.2256/srv1cv83 /etc/init.d/srv1cv83
| 1 | ln-sopt1cv8x86_648.3.17.2256srv1cv83etcinit.dsrv1cv83 |
systemctl daemon-reload
| 1 | systemctl daemon-reload |
Для платформы 8.3.20 или выше
Регистрируемся в systemd
systemctl link /opt/1cv8/x86_64/8.3.21.1393/srv1cv8-8.3.21.1393@.service
| 1 | systemctl linkopt1cv8x86_648.3.21.1393srv1cv8-8.3.21.1393@.service |
И повторяем шаги выше по активации запуску служб
Все запустилось и работает нормально.
Examples
To dump a database called mydb into a SQL-script file:
$ pg_dump mydb > db.sql
To reload such a script into a (freshly created) database named newdb:
$ psql -d newdb -f db.sql
To dump a database into a custom-format archive file:
$ pg_dump -Fc mydb > db.dump
To dump a database into a directory-format archive:
$ pg_dump -Fd mydb -f dumpdir
To dump a database into a directory-format archive in parallel with 5 worker jobs:
$ pg_dump -Fd mydb -j 5 -f dumpdir
To reload an archive file into a (freshly created) database named newdb:
$ pg_restore -d newdb db.dump
To dump a single table named mytab:
$ pg_dump -t mytab mydb > db.sql
To dump all tables whose names start with emp in the detroit schema, except for the table named employee_log:
$ pg_dump -t 'detroit.emp*' -T detroit.employee_log mydb > db.sql
To dump all schemas whose names start with east or west and end in gsm, excluding any schemas whose names contain the word test:
$ pg_dump -n 'east*gsm' -n 'west*gsm' -N '*test*' mydb > db.sql
The same, using regular expression notation to consolidate the switches:
$ pg_dump -n '(east|west)*gsm' -N '*test*' mydb > db.sql
To dump all database objects except for tables whose names begin with ts_:
$ pg_dump -T 'ts_*' mydb > db.sql
To specify an upper-case or mixed-case name in -t and related switches, you need to double-quote the name; else it will be folded to lower case (see ). But double quotes are special to the shell, so in turn they must be quoted. Thus, to dump a single table with a mixed-case name, you need something like
Использование оболочки PostgreSQL (psql)
Та же функциональность может быть достигнута с помощью оболочки PostgreSQL. Откройте оболочку PostgreSQL, выполнив поиск по ключевому слову «psql» в строке поиска. Нажмите на приложение оболочки MySQL и напишите имя локального хоста, который вы использовали. Теперь обязательно добавьте правильное имя вашей базы данных, в которой вы хотите выполнить переиндексацию, вместе с правильным номером порта. После этого вам будет предложено добавить имя пользователя и пароль для пользователя вашей базы данных. Вы также можете использовать базу данных «Postgres» и имя пользователя, то есть по умолчанию. Ваша оболочка будет готова к использованию.
![]()
Посмотрим, сколько индексов у нас в таблице «Ftest». Чтобы просмотреть их, используйте команду «\d+» с именем таблицы «Ftest». Вывод ниже показывает общее количество 2 индексов, найденных в этой таблице, т. е. iftest и inftest. Мы будем переиндексировать эти индексы в следующих запросах.
![]()
Используя ту же команду «\d+», мы получили индексы, отображаемые для таблицы «Значения». Он показывает единый индекс для этой таблицы, как показано ниже. Мы также будем переиндексировать его.
![]()
Начнем сначала переиндексировать таблицу «Ftest». Отбросьте инструкцию «REINDEX» в оболочке PostgreSQL с именем таблицы, т. е. Ftest. Это успешно, и теперь таблица переиндексирована. Полученное в результате слово «REINDEX» является доказательством нашего успеха здесь.

![]()
Чтобы переиндексировать схему PostgreSQL с именем «public», мы должны использовать ту же команду REINDEX с заголовком «SCHEMA». Это будет успешным снова в соответствии с результатом. Слово «REINDEX» — это сообщение об успехе на нашем экране.
![]()
Чтобы воссоздать или деиндексировать одну базу данных, необходимо указать имя базы данных. Только записи, относящиеся к этой базе данных, будут проиндексированы, и никакая другая база данных не будет изменена.
![]()
Вы обнаружите, что не можете переиндексировать другую базу данных, кроме открытой в данный момент, в соответствии с приведенной ниже командой.
![]()
Возможные ошибки
Рассмотрим некоторые проблемы, с которыми можно столкнуться при работе с дампами PostgreSQL.
Input file appears to be a text format dump. please use psql.
Причина: дамп сделан в текстовом формате, поэтому нельзя использовать утилиту pg_restore.
Решение: восстановить данные можно командой psql <имя базы> < <файл с дампом> или выполнив SQL, открыв файл, скопировав его содержимое и вставив в SQL-редактор.
No matching tables were found
Причина: Таблица, для которой создается дамп не существует. Утилита pg_dump чувствительна к лишним пробелам, порядку ключей и регистру.
Решение: проверьте, что правильно написано название таблицы и нет лишних пробелов.
Причина: Утилита pg_dump чувствительна к лишним пробелам.
Решение: проверьте, что нет лишних пробелов.
Aborting because of server version mismatch
Причина: несовместимая версия сервера и утилиты pg_dump. Может возникнуть после обновления или при выполнении резервного копирования с удаленной консоли.
Решение: нужная версия утилиты хранится в каталоге /usr/lib/postgresql/<version>/bin/. Необходимо найти нужный каталог, если их несколько и запускать нужную версию. При отсутствии последней, установить.
No password supplied
Причина: нет системной переменной PGPASSWORD или она пустая.
Решение: либо настройте сервер для предоставление доступа без пароля в файле pg_hba.conf либо экспортируйте переменную PGPASSWORD (export PGPASSWORD или set PGPASSWORD).
Неверная команда \
Причина: при выполнении восстановления возникла ошибка, которую СУБД не показывает при стандартных параметрах восстановления.
Решение: запускаем восстановление с опцией -v ON_ERROR_STOP=1, например:
psql -v ON_ERROR_STOP=1 users < /tmp/users.dump
Теперь, когда возникнет ошибка, система прекратит выполнять операцию и выведет сообщение на экран.